正文
女友做销售,需要搜集一些客户资料(公司名称、联系电话、联系人),我一问,竟然是从 58 上一个一个找?!?!
作为一名帅气负责的程序员~~,当然要为女友分担压力,心里一想,使用爬虫是不是非常方便。
网上简单的搜了一下资料,直接开始写代码,作为一名前端,首选肯定是 Nodejs,使用到的库 :
superagent : Nodejs 一个轻量级的 ajax 库
cheerio : Nodejs 版本的 jQuery,解析 HTML 非常方便
eventproxy : 检测事件执行
async : 控制并发,限制流量。
爬取的网页是 58 企业名录: http://qy.58.com/zz/
1.首先获取到需要爬取的企业列表:
var catchUrl = 'http://qy.58.com/zz/'
var companyUrls = [] // 需要爬的企业列表
superagent.get(catchUrl)
.end(function (err, sres) {
if (err) {
return next(err)
}
var $ = cheerio.load(sres.text)
// 遍历每个企业
$('.compList a').each(function (index, element) {
var $element = $(element)
companyUrls.push($element.attr('href'))
})
companyUrls = companyUrls.distinct() // 去重
})
2.遍历企业列表来获取企业信息(不过这个爬到的企业电话是图片):
function getCompanyInfo (url) {
var company = {
companyName: '',
companyContact: '',
contactPhone: []
}
superagent.get(url)
.end(function (err, res) {
if (err) {
return next(err)
}
var $ = cheerio.load(res.text)
company.companyName = $('.businessName').eq(0).attr('title')
var companyContact = $('.basicMsgListo.basicMsgList li').eq(1).text().split(':')[1];
company.companyContact = companyContact == undefined ? '' : companyContact.trim();
$('.basicMsgListo.basicMsgList li').eq(3).find('img').each(function(index, element) {
var $element = $(element)
var phoneSrc = $element.attr('src')
company.contactPhone.push(phoneSrc)
})
// 每个企业的信息
console.log(company)
})
}
3.信息基本获取到,对爬取的流程进行优化,比如限流和事件监测。
// 限流,并发请求 5 个
var concurrencyCount = 0; // 并发连接数的计数器
async.mapLimit(companyUrls, 5, function (url, callback) {
getCompanyInfo(url, callback)
// cb()
}, function (err, result) {
// console.log('final:');
})
// 每次获取企业信息时触发一次 'companyInfo'
function getCompanyInfo (url, cb) {
...
concurrencyCount++;
console.log('现在的并发数是', concurrencyCount, ',正在抓取的是', url);
superagent.get(url)
.end(function (err, res) {
...
concurrencyCount--;
cb(null, url + ' 爬取完成!')
ep.emit('companyInfo', company)
}
}
// 监听遍历次数
ep.after('companyInfo', companyUrls.length, function (companys) {
companyList = companys
console.log(companys)
})
4.完整代码
var http = require("http"),
url = require("url"),
superagent = require("superagent"),
cheerio = require("cheerio"),
async = require("async"),
eventproxy = require('eventproxy');
var catchUrl = 'http://qy.58.com/zz/'
var companyUrls = [] // 需要爬的企业列表
var companyList = [] // 公司列表
// 并发连接数的计数器
var concurrencyCount = 0;
var ep = new eventproxy()
// 数组去重
Array.prototype.distinct = function(){
var arr = this,
result = [],
i,
j,
len = arr.length;
for(i = 0; i < len; i++){
for(j = i + 1; j < len; j++){
if(arr[i] === arr[j]){
j = ++i;
}
}
result.push(arr[i]);
}
return result;
}
function app() {
superagent.get(catchUrl)
.end(function (err, sres) {
if (err) {
return next(err)
}
var $ = cheerio.load(sres.text)
// 遍历每个企业
$('.compList a').each(function (index, element) {
var $element = $(element)
companyUrls.push($element.attr('href'))
})
companyUrls = companyUrls.distinct() // 去重
// 监听遍历次数
ep.after('companyInfo', companyUrls.length, function (companys) {
companyList = companys
console.log(companys)
})
// 限流
async.mapLimit(companyUrls, 5, function (url, callback) {
getCompanyInfo(url, callback)
// cb()
}, function (err, result) {
// console.log('final:');
})
// console.log(companyUrls)
})
}
function getCompanyInfo (url, cb) {
var company = {
companyName: '',
companyContact: '',
contactPhone: []
}
concurrencyCount++;
console.log('现在的并发数是', concurrencyCount, ',正在抓取的是', url);
superagent.get(url)
.end(function (err, res) {
if (err) {
return next(err)
}
var $ = cheerio.load(res.text)
company.companyName = $('.businessName').eq(0).attr('title')
var companyContact = $('.basicMsgListo.basicMsgList li').eq(1).text().split(':')[1];
company.companyContact = companyContact == undefined ? '' : companyContact.trim();
$('.basicMsgListo.basicMsgList li').eq(3).find('img').each(function(index, element) {
var $element = $(element)
var phoneSrc = $element.attr('src')
company.contactPhone.push(phoneSrc)
})
// console.log(company)
// companyList.push(company)
concurrencyCount--;
cb(null, url + ' 爬取完成!')
ep.emit('companyInfo', company)
})
}
app()
5.对获取到的数据进行展示
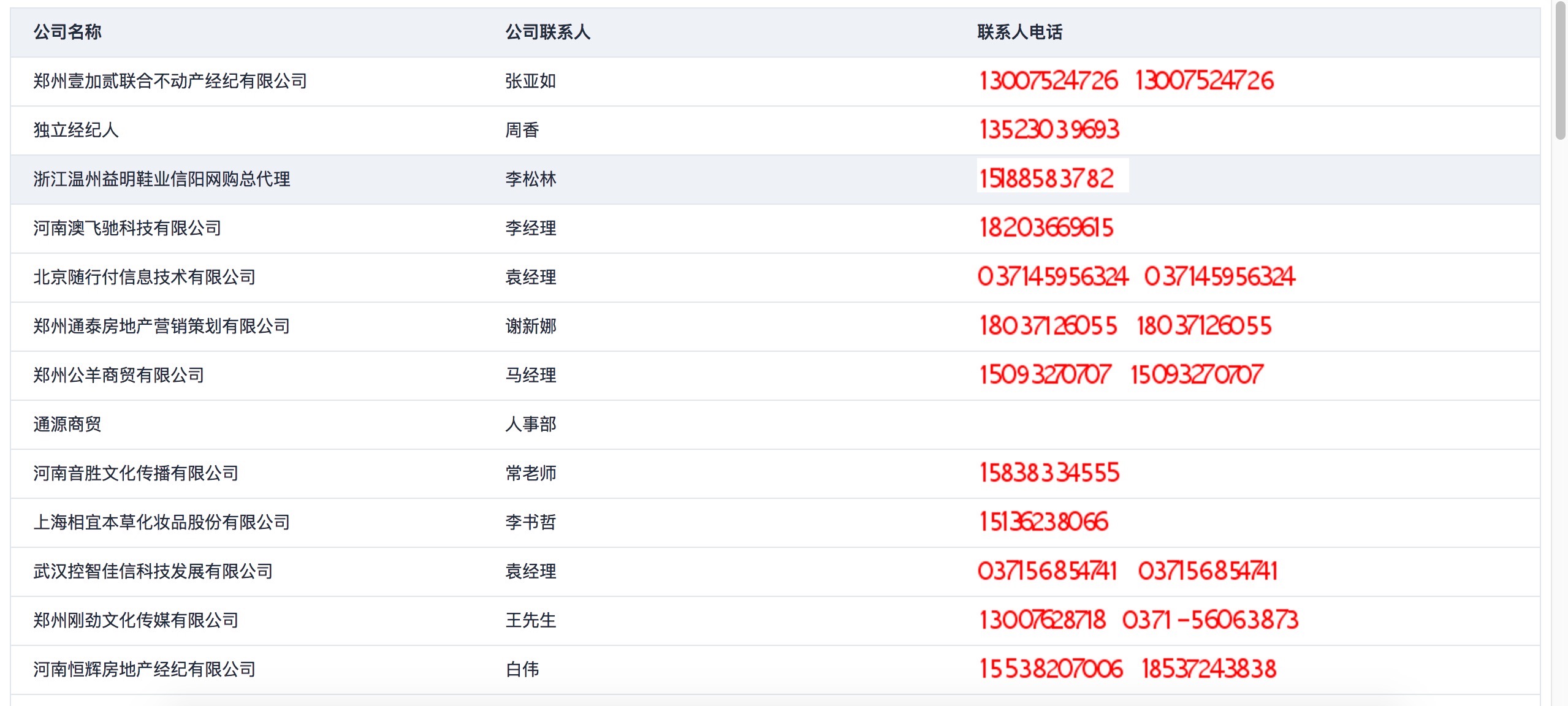
补充
nodejs 默认的编码方式为 utf-8,如果原始网页的编码方式不一致会出现乱码。
解决办法:
var charset = require('superagent-charset'),
superagent = charset(require('superagent'));
superagent.get(url)
.charset('gbk')
.end(function (err, sres) {
}